3. Setting up TF-IDF in Python and Scikit Learn ¶
3.1. Key Concepts in this Notebook¶
Importing the required libraries
Preparing the data properly
Setting up TF-IDF with Scikit Learn
3.2. Introduction¶
In the last notebook, we learned about Scikit-Learn. In this notebook, we are going to take that knowledge and implement the TF-IDF algorithm from Scikit-Learn, but before we do that, we have to consider one very important thing: the state of our data. Whenever you are using algorithms, it is always essential to think about what form does the algorithm expect. The first part of this notebook will, therefore, be dedicated to explaining the data and preparing it for the TF-IDF algorithm. It is important to note that this notebook will be code-centric.
Finally, because this notebook is designed to be from beginning to end of a TF-IDF implementation, from preparing the data to cleaning to TF-IDF to Clustering to data visualization, this notebook will be longer than the previous ones.
3.3. The TRC Data¶
In every real world scenario you will know the data that you are working with. In this section I think it’s worthwhile to spend a little bit of time talking about the data that we are going to be working with throughout this notebook. The first bit of data that we’re going to be working with is a collection of descriptions of violence from apartheid South Africa from the 20th century. They come out of the Truth and Reconciliation Commission in the early 2000s. The Truth and Reconciliation Commission or the TRC was a body put together at the end of the twentieth century to catalog the violence that befell victims during the apartheid period. The first dataset is what is known as Volume 7 of the TRC Final Report. It is organized as a collection of individuals and a brief description of the violence that befell them and the victim’s age. Descriptions of violence are not structured in any way. Instead they have rich metadata within them. This metadata consists of things like dates, places, and other organizations during the 20th century.
The data that I have prepared for you is a JSON file of the TRC Volume 7 report. The JSON file is structured as a dictionary with two keys the first key is names and that corresponds to a list of the victim names. The second key is descriptions. This is the key piece of the data that we will be working with. These are the descriptions of violence and we are trying to identify topics within these descriptions.
3.4. Preparing the Data¶
In this section of the notebook we will begin importing and manipulating and working with our TRC dataset and in order to do that you need to be familiar with how to import JSON data in Python so in this first block of code we will be doing just that. I always find that writing out a basic function for reading Json data is always useful because you can use the function throughout your script without having to write 3 lines of code and instead simply writing one. We are going to call this function load_data.
import json
def load_data(file):
with open (file, "r", encoding="utf-8") as f:
data = json.load(f)
return (data)
With this function now in place we can import our JSON data that contains our TRC data set which is under the data subfolder. In the next line, we call this function to achieve that task.
trc_data = load_data("data/trc_dn.json")
Now that we have loaded the data, let’s create two separate objects, one for the anmes in the dataset and another for the descriptions. There are better ways to do this in Python with libraries like Pandas, but I do not want to introduce another library into the mix in this textbook.
names = trc_data["names"]
descriptions = trc_data["descriptions"]
Now that we have the objects created, it’s probably a good idea to print of the first index of each to make sure that they are what we expect and to print off the length of each list to make sure that they are the same length.
print (names[0])
print (descriptions[0])
print (len(names))
print (len(descriptions))
AARON, Thabo Simon
An ANCYL member who was shot and severely injured by SAP members at Lephoi, Bethulie, Orange Free State (OFS) on 17 April 1991. Police opened fire on a gathering at an ANC supporter's house following a dispute between two neighbours, one of whom was linked to the ANC and the other to the SAP and a councillor.
21747
21747
This is precisely what we want to see. Both lists are the same length and index 0 for names aligns with the correct corresponding description. This is also a good chance to see what this data looks like. This description is a fair representation of the format and length of all other descriptions in this dataset.
Below, we will use the names to plot the data on a graph, but for now we will strictly be working with the descriptions list. The reason for this is because these are the texts that we want to cluster through TF-IDF and K-Means.
3.5. Cleaning the Data¶
Now that we have the data that we need for processing, it is time to start cleaning the data. When cleaning text for TF-IDF and topic modeling, it is often good practice to remove certain things from the text that may throw off the algorithms. The specific things you choose to remove from texts will vary depending on the texts you are working with, but there are generally certain words for each language that you will want to remove. These are called stop words.
In English, stop words will be articles, such as ‘the’, ‘an’, and ‘a’ or the verb “to be”. These words are often removed from texts because they occur so frequently that they offer nothing unique about the texts at hand. In other words, they are so common that they do not aid in the clustering of texts. This is because clustering seeks to find particular features of texts and then identify the texts with common overlapping features. Stop words would make all texts overlap significantly. We remove these words to force clustering to focus on the more important words.
In addition to this, we also often need to develop our own stop words for these specific texts, or a general domain. In our case, these texts have a lot of dates and AC numbers that correspond to other records. While these are significant pieces of metadata, these both throw off the clustering. If we were interested in seeing how dates overlap, there are better ways of performing that task. For those interested, see my Named Entity Recognition Textbook.
The functions below will clean our text in the above mentioned manner. There are annotations to explain each section of the code. If more explanation is needed, please leave a comment on GitHub.
import string
from nltk.corpus import stopwords
import re
def remove_stops(text, stops):
#uses regex to remove all AC numbers
text = re.sub(r"AC\/\d{1,4}\/\d{1,4}", "", text)
#removes all stop words, including months
words = text.split()
final = []
for word in words:
if word not in stops:
final.append(word)
#reassembles the text without stop words
final = " ".join(final)
#removes all punctuation
final = final.translate(str.maketrans("", "", string.punctuation))
#removes all numbers
final = "".join([i for i in final if not i.isdigit()])
#eliminates double white spaces
while " " in final:
final = final.replace(" ", " ")
return (final)
def clean_docs(docs):
#gets the NLTK's stopword list for English
stops = stopwords.words("english")
#Grabs all the months from data/months.json
months = load_data("data/months.json")
#combines the two to make a master stopword list
stops = stops+months
#empty new list to store the cleaned docs
final = []
#iterate over all docs and cleans them to be a
#single sentence with no unwanted words
for doc in docs:
clean_doc = remove_stops(doc, stops)
final.append(clean_doc)
return (final)
Now comes the time to clean all of our documents. We will use one line of code to pass all descriptions to clean_docs().
cleaned_docs = clean_docs(descriptions)
After cleaning my documents, I always find it is good to print off a sample of the before and after to see that my functions are working as intended. So, let’s do that here.
print ("Original Text:")
print (descriptions[0]+"\n")
print ("Cleaned Text:")
print (cleaned_docs[0])
Original Text:
An ANCYL member who was shot and severely injured by SAP members at Lephoi, Bethulie, Orange Free State (OFS) on 17 April 1991. Police opened fire on a gathering at an ANC supporter's house following a dispute between two neighbours, one of whom was linked to the ANC and the other to the SAP and a councillor.
Cleaned Text:
An ANCYL member shot severely injured SAP members Lephoi Bethulie Orange Free State OFS Police opened fire gathering ANC supporters house following dispute two neighbours one linked ANC SAP councillor
As we can see from these two outputs, the original text has been heavily altered and cleaned. Notice, for example, the removal of the date. Now that we have the data fully cleaned, it is time to begin setting up the TF-IDF algorithm with Scikit-Learn.
3.6. Implementing TF-IDF in Python¶
Implementing TF-IDF in Python requires us to import a few things from the Scikit Learn library. Remember, in Python Scikit Learn is “sklearn”. So, let’s import those things now.
# A lot of this section comes from the Scikit Learn documentation and various blogs including the following:
#https://towardsdatascience.com/applying-machine-learning-to-classify-an-unsupervised-text-document-e7bb6265f52
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
First, we import the TfidfVectorizer. This is going to be what allows us to perform TF-IDF in just a few lines of code. Second, we import KMeans. This will be what allows us to cluster the TF-IDF of each key word in each text.
Now that we have the libraries imported, we can begin to work with them. First, let’s make our vectorizer. This will be our TF-IDF algorithm. It will have several functions that we can call. For now, though, let’s focus on the parameters.
lowercase => allows us to lowercase our data.
max_features => this is how many words out of the entire corpus we want to take into account. Here, we will use 100. The higher the number, the more computational expensive the tasks are to run. I have chosen 100 for this demonstration somewhat at random, but it works fairly well for our purposes.
max_df => this is a float that tells the algorithm to ignore any word that occurs in 80% of the documents.
min_df => this is an integer that tells the algorithm to ignore words that do not occur more than 5 times in the entire corpus.
ngram_range => this is a tuple with index 0 being the smallest number of words to consider with the second index being the largest, i.e. 2 for bigram and 3 for trigrams. (1, 3) means the algorithm should consider anything from a unigram (one word) to trigram (three words) as a concept.
stop_words => this is the language you are working with and you are telling the algorithm to ignore the predefined set of stopwords. This is a bit excessive since we already did this with NLTK.
vectorizer = TfidfVectorizer(
lowercase=True,
max_features=100,
max_df=0.8,
min_df=5,
ngram_range = (1,3),
stop_words = "english"
)
Now that we have created the vectorizer, let’s pass our documents to the algorithm with the method fit_transform(). This will pass all documents to the algorithm and vectorize them.
vectors = vectorizer.fit_transform(cleaned_docs)
Here, we can see the results of the vectors of the first document. This output is a tuple which indicates the keyword and the TF-IDF score. In this form, however, it is a bit hard to decipher.
print (vectors[0])
(0, 5) 0.31417904033665145
(0, 37) 0.26764577237075254
(0, 92) 0.17885669660417403
(0, 2) 0.35997263491995035
(0, 71) 0.27507572242905154
(0, 54) 0.20314225251689294
(0, 77) 0.5249891606885219
(0, 42) 0.24755257133949066
(0, 80) 0.3047379292177127
(0, 82) 0.19595009171387526
(0, 53) 0.28809076545860496
feature_names = vectorizer.get_feature_names()
By using the method get_feature_names(), we can get an easier to read text representation of our key words. Let’s look at the most common first.
print (feature_names[0])
allegedly
dense = vectors.todense()
By using the method todense(), we can convert that vector into a larger representation and each word’s TF-IDF score. Each number corresponds to a word. Those words that are keywords have a TF-IDF score, while those represented by 0 are words that did not make it into our max_features. In other words, they are irrelevant words.
print (dense[0])
[[0. 0. 0.35997263 0. 0. 0.31417904
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0.26764577 0. 0. 0. 0.
0.24755257 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.28809077
0.20314225 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.27507572
0. 0. 0. 0. 0. 0.52498916
0. 0. 0.30473793 0. 0.19595009 0.
0. 0. 0. 0. 0. 0.
0. 0. 0.1788567 0. 0. 0.
0. 0. 0. 0. ]]
To work with this data, let’s reconvert it into a list with the command below.
denselist = dense.tolist()
This is what that same data looks like when printed off as a list. Again, this is our first document represented with its TF-IDF scores for each word.
print (denselist[0])
[0.0, 0.0, 0.35997263491995035, 0.0, 0.0, 0.31417904033665145, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.26764577237075254, 0.0, 0.0, 0.0, 0.0, 0.24755257133949066, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.28809076545860496, 0.20314225251689294, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.27507572242905154, 0.0, 0.0, 0.0, 0.0, 0.0, 0.5249891606885219, 0.0, 0.0, 0.3047379292177127, 0.0, 0.19595009171387526, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.17885669660417403, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
Now, let’s convert every document from its TF-IDF scores to a list of key words. This will be essential for clustering below. In the code below, we run each description across the denselist and check if each word appears in the denselist. If it does (i.e. if it is one of the 100 important max feature words), then we keep it and append that list of words to all_keywords. This object will be all the documents in a list. Each index (document) will now be a list of words.
all_keywords = []
for description in denselist:
x=0
keywords = []
for word in description:
if word > 0:
keywords.append(feature_names[x])
x=x+1
all_keywords.append(keywords)
Let’s take a look at what we have been able to do to our document 0 by looking at its original state, cleaned state, and just the key words.
print ("Original Text:")
print (descriptions[0]+"\n")
print ("Cleaned Text:")
print (cleaned_docs[0]+"\n")
print ("Only Keywords Text:")
print (all_keywords[0])
Original Text:
An ANCYL member who was shot and severely injured by SAP members at Lephoi, Bethulie, Orange Free State (OFS) on 17 April 1991. Police opened fire on a gathering at an ANC supporter's house following a dispute between two neighbours, one of whom was linked to the ANC and the other to the SAP and a councillor.
Cleaned Text:
An ANCYL member shot severely injured SAP members Lephoi Bethulie Orange Free State OFS Police opened fire gathering ANC supporters house following dispute two neighbours one linked ANC SAP councillor
Only Keywords Text:
['anc', 'anc supporters', 'house', 'injured', 'member', 'members', 'police', 'sap', 'severely', 'shot', 'supporters']
3.7. K-Means Clustering¶
Now that our data is nothing more than a list of lists of key words for each document, we can use these features to see where there is overlap. This is called clustering and one method of clustering is K-Means which seeks to place every document into a cluster to which it has the most similarity. In the below code, we define true_k as the number of clusters. In this example, I am telling it to find 5 clusters. In the video below, I used 20, but as we will see for plotting it is easier to have 5.
true_k = 5
model = KMeans(n_clusters=true_k, init="k-means++", max_iter=100, n_init=1)
Now that we have created the K-Means model, its time to cluster the data. We will do this by fitting the vectors to the model. In this scenario, we are using the TF-IDF scores from the descriptions to formulate the basis for our clusters.
model.fit(vectors)
order_centroids = model.cluster_centers_.argsort()[:, ::-1]
terms = vectorizer.get_feature_names()
Now that we have done that, let’s see what our 5 clusters look like as arrays. These arrays are a list of the keywords most associated with each cluster represented by their numerical value.
print (order_centroids)
[[92 2 39 17 64 22 88 35 60 41 37 11 72 43 73 29 6 3 5 49 25 50 87 44
9 98 8 47 48 21 89 26 0 52 46 36 93 23 65 38 74 42 40 66 59 18 30 31
82 19 75 51 12 32 58 96 28 99 80 68 76 54 70 53 13 14 84 97 20 45 10 69
1 71 86 95 90 33 34 24 81 15 83 78 77 16 4 55 7 94 27 61 56 63 62 67
79 85 91 57]
[83 24 82 90 2 4 91 88 39 3 92 60 41 64 22 54 49 72 59 50 5 6 11 0
73 96 29 42 46 40 53 84 75 71 43 68 77 66 65 97 30 23 74 31 35 58 93 98
44 32 76 20 12 55 51 70 45 99 86 47 48 28 37 69 1 87 80 13 25 17 95 21
34 33 56 78 67 38 15 16 36 26 10 8 63 62 61 7 14 18 9 19 52 79 27 81
94 89 85 57]
[85 61 62 63 51 65 8 13 50 49 29 19 18 41 39 17 64 38 92 37 89 3 2 88
36 35 22 73 72 6 74 23 9 11 40 26 5 52 82 24 83 93 46 66 90 4 59 43
0 76 91 12 14 42 68 87 70 32 25 84 54 44 53 80 58 98 28 71 81 77 10 16
34 55 33 1 69 60 47 86 67 7 48 94 45 96 97 95 79 56 15 78 20 21 57 75
27 30 31 99]
[54 77 55 71 20 82 27 14 53 80 94 59 96 81 42 7 15 10 58 88 95 2 97 86
84 0 24 83 98 45 3 28 46 99 72 22 78 35 6 76 68 25 75 37 16 64 11 79
56 32 73 21 52 87 70 12 60 90 29 92 17 69 8 13 49 26 1 9 4 39 5 50
23 33 74 65 34 43 67 47 41 38 48 66 36 30 57 31 44 93 51 40 91 89 85 18
61 62 63 19]
[ 1 56 33 34 67 42 57 46 68 78 54 11 69 96 79 16 53 2 70 82 45 13 64 24
39 29 71 12 80 97 58 84 20 83 37 92 95 28 77 98 35 41 86 72 43 88 60 0
65 99 10 15 32 25 75 94 49 50 44 22 51 27 40 90 26 73 87 5 3 59 17 6
76 30 31 7 52 8 14 9 4 55 66 47 48 21 81 38 91 93 61 89 18 19 23 74
36 63 62 85]]
Let’s look at the first word from the first cluster, number 92. We can find that word by looking it up in our terms list.
print (terms[92])
supporters
Since we can do that with one word, we can automate the entire process of converting all numbers into a list of key words for each cluster with the below code. Here, I am limiting the list to just the first 10 words for each cluster.
i = 0
for cluster in order_centroids:
print (f"Cluster {i}")
for keyword in cluster[0:10]:
print (terms[keyword])
print ("")
i=i+1
Cluster 0
supporters
anc
ifp
burnt
near
conflict
supporter
home
natal
ifp supporters
Cluster 1
shot dead
dead
shot
supporter shot
anc
anc supporter shot
supporter shot dead
supporter
ifp
anc supporter
Cluster 2
sonkombo
ndwedwe
ndwedwe kwazulu
ndwedwe kwazulu near
kwazulu near durban
near durban
arson
attacks
kwazulu near
kwazulu
Cluster 3
members
sap
members sap
police
cape
shot
detained
beaten
member
severely
Cluster 4
amnesty
mk
granted
granted amnesty
operatives
injured
mk operatives
killed
people
security
And Viola, just like that we have all 22,000 descriptions clusterd into 5 categories. I know what you may be thinking, though. How do we see where those documents are. The answer is addressed below when we plot the data. In order to walk through this portion of notebook, check out the video below.
%%html
<div align="center">
<iframe width="560" height="315" src="https://www.youtube.com/embed/i74DVqMsRWY" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</div>
3.8. Plotting the Data¶
This portion of the notebook is perhaps best illustrated with the video below. The code below has already been executed so that you can see the data plotted out on a graph. Each node on the graph represents a description. Each color represents a cluster.
#A lot of this section was obtained from https://stackoverflow.com/questions/27494202/how-do-i-visualize-data-points-of-tf-idf-vectors-for-kmeans-clustering
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
kmean_indices = model.fit_predict(vectors)
pca = PCA(n_components=2)
scatter_plot_points = pca.fit_transform(vectors.toarray())
colors = ["r", "b", "m", "y", "c"]
x_axis = [o[0] for o in scatter_plot_points]
y_axis = [o[1] for o in scatter_plot_points]
fig, ax = plt.subplots(figsize=(50, 50))
ax.scatter(x_axis, y_axis, c=[colors[d] for d in kmean_indices])
<matplotlib.collections.PathCollection at 0x16612b1ddf0>
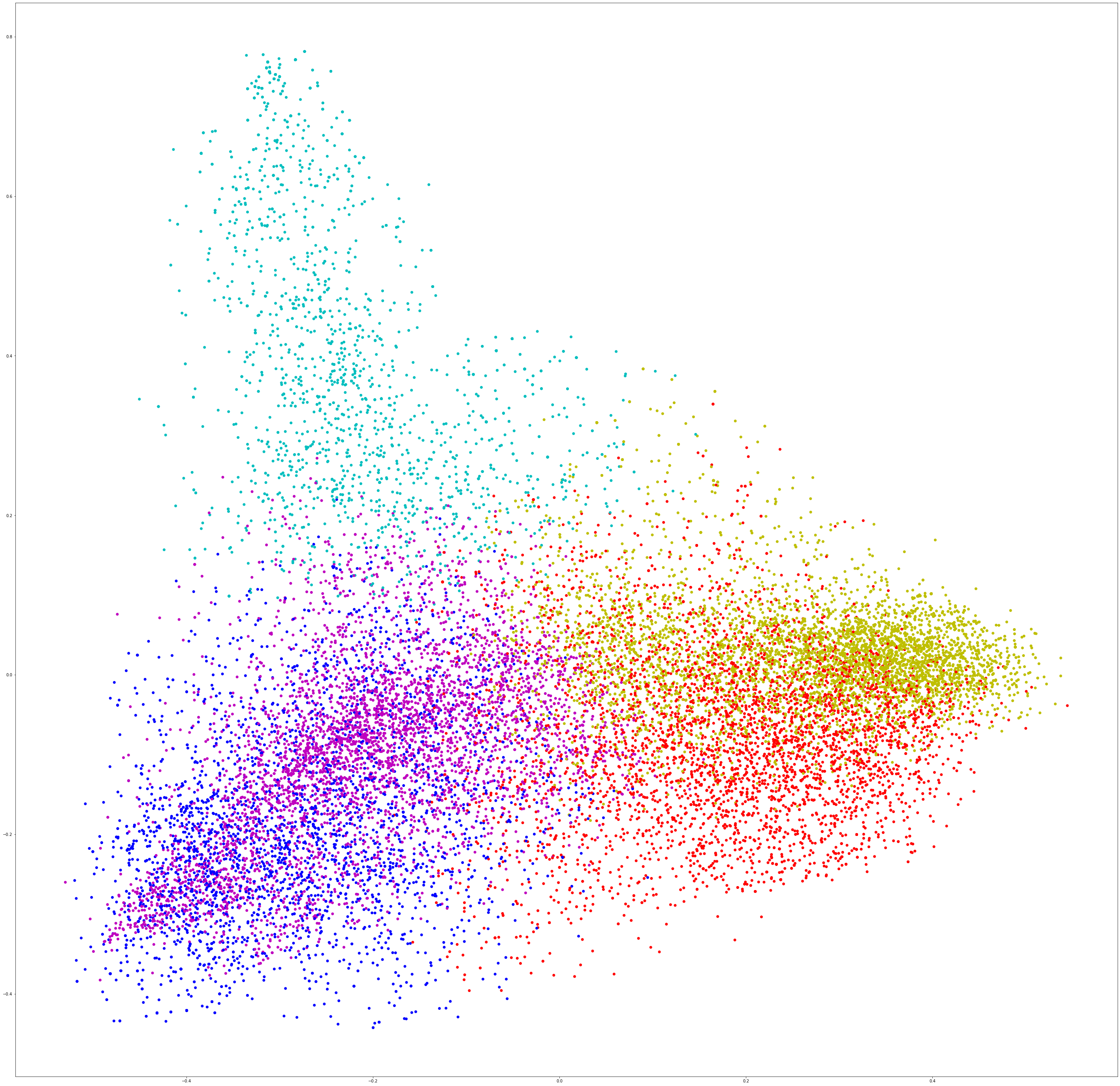
fig, ax = plt.subplots(figsize=(50, 50))
ax.scatter(x_axis, y_axis, c=[colors[d] for d in kmean_indices])
for i, txt in enumerate(names):
ax.annotate(txt[0:5], (x_axis[i], y_axis[i]))
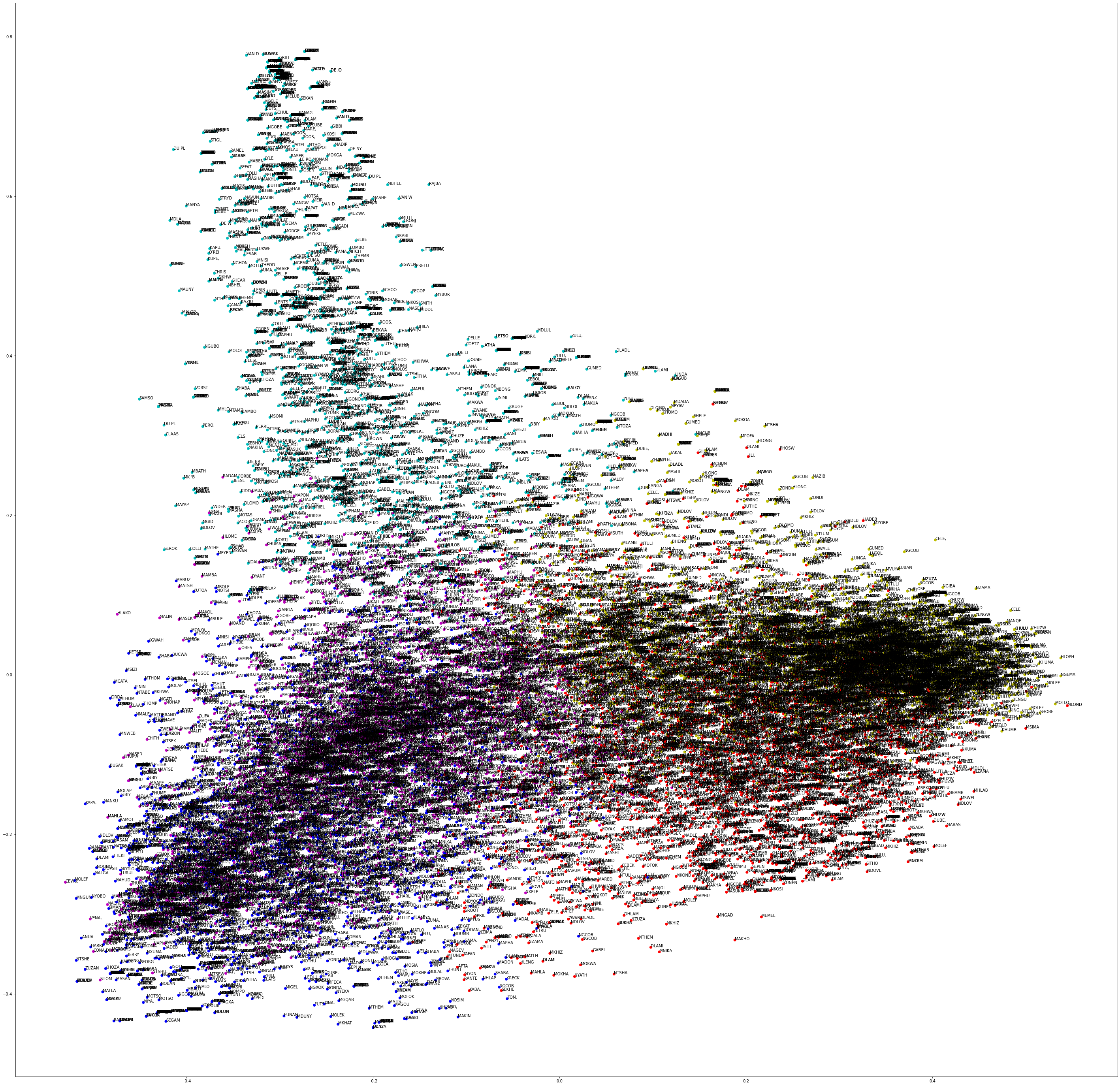
%%html
<div align="center">
<iframe width="560" height="315" src="https://www.youtube.com/embed/B0BkUNMqfSo" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</div>