1. Introduction to Topic Modeling ¶
1.1. Introduction to this Series of Notebooks¶
These notebooks are designed for those interested in performing topic modeling or text classification via Python. They are intended those who have limited coding experience and no background in natural language processing (NLP). A basic understanding of Python is necessary to partake fully in this series, however, those with no coding experience will still gain a foundational understanding of topic modeling and text classification, the common problems in these fields, and solutions to those problems. For those interested in gaining a quick introduction to Python, please see my series designed for digital humanists at PythonHumanities.com.
The purposes of these notebooks is fivefold.
Introduce the reader to the core concepts of topic modeling and text classification
Provide an introduction to three libraries (Scikit Learn, Gensim, and spaCy) for those with limited Python knowledge
Detail the problems and solutions to working with various topic modeling problems
Detail the different approaches to topic modeling and text classification (rules-based and machine learning-based)
Provide code that will be easily replicable for readers who wish to apply these methods to their own domains.
These notebooks shall serve as a guide for those experiencing similar problems in all domains. Throughout these notebooks, we will work with two datasets. The first is a collection of short descriptions of violence in Apartheid South Africa, which comes from Volume 7 of the Truth and Reconciliation Commission’s final report (hereafter, TRC Vol. 7). The second is a collection of oral testimonies held at the United States Holocaust Memorial Museum (hereafter, USHMM Oral Tesimonies). I will explain each of these datasets in detail when we first encounter them. I have chosen these two datasets because they represent different types of data, from brief statements (TRC Vol. 7) to long testimonies (USHMM Oral Testimonies).
Key concepts and terminology will be emboldened. If there are mistakes in grammar, spelling, or code, please reach out to me via twitter (@wjb_mattingly) and I will update the notebooks accordingly.
1.2. Key Concepts in this Notebook¶
natural language processing (NLP)
natural language understanding (NLU)
topic modeling
tokens and tokenization
multi-word tokens
spans
pipelines
1.3. What is Natural Language Processing?¶
Topic modeling and text classification (addressed below) is a branch of natural language understanding, better known as NLP. It is closely connected to natural language understanding, better known as NLU. NLP is the process by which a researcher uses a computer system to parse human language and extract important metadata from texts. The purpose of NLP is to perform, among other things, distant reding.
Distant reading has a long history extending to the late-twentieth century. It is commonly used when the quantity of texts in a given corpus prevent a researcher (or a team of researchers) from reading the corpus closely in its entirety. In order to make sense of that large corpus, the researcher will often pass certain tasks to a computer with the understanding that there is a margin of error. This margin of error is accepted in exchange for the ability to gain a larger, distant understanding of that corpus.
The metadata from these tasks can then be used to get a sense of the texts without reading them closely, hence the term distant reading.
To get a better understanding of how these fields relate to one another, please see the image below.
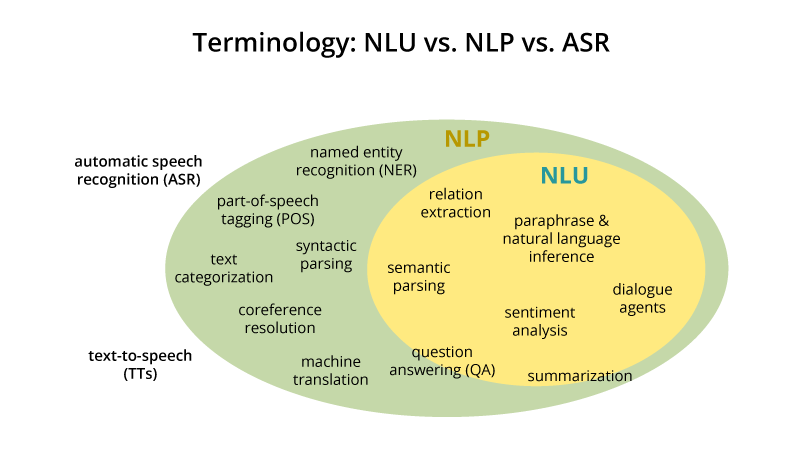
This image is commonly shared across various NLP tutorials and for good reason. It accuarately portrays the diverse field of NLP and its close partner fields of NLU and ASR. The goal of NLU is to give a computer system a text (or collection of texts) and produce some sense of understanding about that text or those texts.
There are various types of tasks that fall under NLU, including paraphrase and natural language inference. This is when a computer system takes an input text of, say 5,000 words, reduces that text to its core components, and outputs a summary of the text. This is a task often used by law firms that need to gain a quick understanding of a large corpus of documents to target their investigation and use their time wisely. Another task is sentiment analysis in which a user gives a computer system a text and the system determines whether it is x or y. This is often used by social media companies to determine if a text is abusive so that they can flag and delete inappropriate content automatically.
A common form of NLP and the subject of these notebooks is topic modeling and text classification. While closely linked and rather similar, they are distinct methods that perform distinct tasks. For topic modeling, we give a computer system a text and it tells us what topic(s) is (are) discussed in it. For text classification, we give a system a text and it classifies it into certain categories. In essense, while NLP is essential for working with textual data in a computer environment by parsing it and identifying its key components, NLU goes one step further and tries to understand that same data the way a human may.
For all NLP and NLU tasks, there are rules-based and machine learning-based approaches. In this notebook, we will be looking at each. Parts Two and Three in this book are focused on clustering and topic modeling. In Part Two, we will explore rules-based methods, such as Term Frequency-Inverse Document Frequency, better known as TF-IDF; and in Part Three we will explore machine learning-based methods, specifically Latent Dirichlet Allocation models, better known as LDA models.
Before we move into those subjects, something should be said of rules-based vs. machine learning-based approaches.
1.4. Rules-Based Methods¶
A rules-based approach to topic modeling uses a set of rules to extract topics from a text. It does this by identifying keywords in each text in a corpus. One of the most common ways to perform this task is via TF-IDF, or term frequency-inverse document frequency. We will discuss this method a lot more in Part Two of these notebooks. Simply put, a TF-IDF looks for a word’s frequency in a single text, respective to that word’s use across the corpus as a whole. If that word occurs infrequently in all other documents, but frequently in one document, then we use rules to identify the document that sees one word used with a high frequency as the chief document of a given topic.
For certain problems, a rules-based approach is particularly useful. As we will see, documents that are shorter, such as tweets, tend to fare better from rules-based approaches.
1.5. Machine Learning-Based Methods¶
Another option to identify topics in a text is via a machine learning-based approach. In this method, we do not give a computer system a set of rules, rather we let the computer generate its own rules to identify topics in a corpus. This is done in two different ways: supervised and unsupervised learning.
In supervised learning, we know the key subjects in a corpus. We give a computer system a set of documents with their corresponding label to teach it to identify the characteristics that make that particular topic or class unique. This is mostly used for text classification.
Another approach is via unsupervised learning. In unsupervised learning, we do not know the topics of our documents and, instead, we want let the system identify those topics and cluster the ones of a highd degree of similarity together. We then examine the words that occur the most frequently in each cluster to get a sense of the topics at hand. The classic example for machine learning topic modeling is LDA, or Latent Dirichlet Allocation. We will learn about this method in far more detail in Part Three.
1.6. Why use Topic Modeling?¶
All of this leads to a vital question: Why use topic modeling? Topic modeling affords researchers the ability to learn a lot about their corpus very quickly. It is often used whent he corpus is so large that no single human could read it in a single lifetime.
In both a rules-based and machine learning-based approach, a researcher can see what major subjects are discussed in a corpus. This information can be used to perform targetted research by weeding out the documents that likely do not contain the information the researcher needs. Additionally, the information drawn from topic modeling can be used to make large deductions about the corpus at hand. We will see that topic modeling can be used to draw imprecise or incorrect conclusions.
It is vital, however, to understand the limitations of topic modeling. There is always a potential for the researcher to use topic modeling to validate a wrong presumption about the data. Throughout this series, I will emphasize methodological steps that can (and should) be taken to limit these mistakes. Despite this potential for error, topic modeling can provide valuable insight, relatively quickly about a large corpus.
1.7. Video¶
In this video, I explain these concepts and outline the future parts of this blog.
%%html
<div align="center">
<iframe width="560" height="315" src="https://www.youtube.com/embed/N0crN8YnF8Y" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</div>