2. Topics and Clusters ¶
2.1. Key Concepts in this Notebook¶
topics
clusters
k-means
2.2. Introduction¶
This notebook will focus on the key terms and terms for topic modeling: topics, clusters, and k-means. Each of these terms will be used throughout this book and it is worth defining them early.
2.3. What are Topics?¶
Topics are labels assigned to textual data that detail the subjects contained within a given text. In topic modeling we try to create computer systems that can assign topics the way a human would. In order to understand this process, it’s best if we take a step back and think about how we assign topics.
To do this, let’s examine these two texts.
Text 1: Thomas enjoys playing basketball. He is an exceptionally good point guard. Text 2: Victoria enjoys playing baseball. She is an exceptionally good at playing first base.
If I asked you to provide two topics to these texts, what might they be? Basketball and baseball are likely two top candidates. Text 1 would have the topic of basketball, while text 2 would have the topic of baseball. Now, let’s consider these same texts, but add two more into the mix.
Text 3: John is a talented chef. He enjoys making pasta professionally. Text 4: Jeff is a talented cook. He owns a pizzaria.
Now, if I asked you to assign two topics to all four texts, what might those topics be? It is likely that your answer changed. No longer are the two topics of baseball and basketball relevant because Text 3 and Text 4 do not align well with those topics. Instead, a better pair of topics might be sports and cooking, or something like that. What changed? The collection of texts in our corpus changed.
What does this demonstrate? It tells us that topics are corpus-dependent, meaning the topics we assign to texts depend on their context against surrounding texts. The same holds true for topic modeling via computer systems.
2.4. What are Clusters?¶
In topic modeling, computer systems do not generate topics, rather they generate a list of high concentration words. Texts that share common terms are clustered together by similarity. A cluster is nothing more than a collection of similar texts. There are various ways to cluster textual data that we will explore throughout this series, but one of the fundamental ones we will use is k-means.
2.5. Brief Introduction to K-Means¶
K-means is a common method of clustering in data science and can be easily implemented via the Python library Scikit-Learn (see Part Two of this book). The K-means method of clustering takes in the textual data and places all documens in k number of clusters. In this scenario, the researcher assigns a numerical variable for k, so if the researcher wished to see all texts clustered into 10 topics, or clusters, the k-means algorithm would find the documents with the greatest degree of similarity and place them in the closest mean cluster. The result is a forced clustering of all texts neatly into 10 clusters. We can then discern their topics by examining the words that overlap between texts in each cluster. As we will see in Part Two, this can be tricky and invovles trial and error.
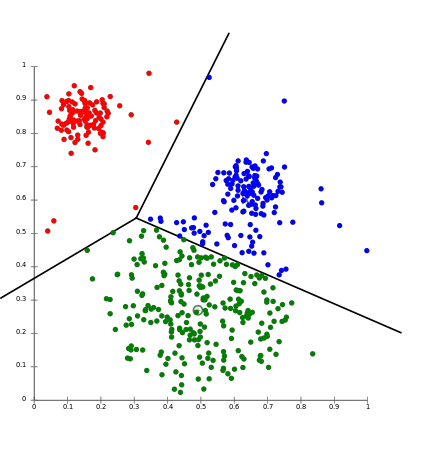
In the example below, we can see a sample output of K-Means clustering. In this image, there are 3 clusters. Notice how all data (dots on the graph) are clustered into one of the three categories. This is the K-Means clustering method at work. Notice also how the blue dot in the top of the graph and the nearby red dots may have similarity or overlap, yet are clustered differently. This is the result of the absolute nature of K-Means clustering.
2.6. Video¶
%%html
<div align="center">
<iframe width="560" height="315" src="https://www.youtube.com/embed/0tkg7t2gsfY" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</div>